

Chatbot Development
Services
Skyrocket Customer Service with our Customized Chatbot Development Services
Helping Businesses Transform with AI Chatbot Development Services
Being one of the professional chatbot companies, we provide custom chatbot development services for your website and apps. Our chatbot developers’ team makes the perfect use of tools and technologies and offer powerful chatbot development from scratch tailored to meet your business needs.
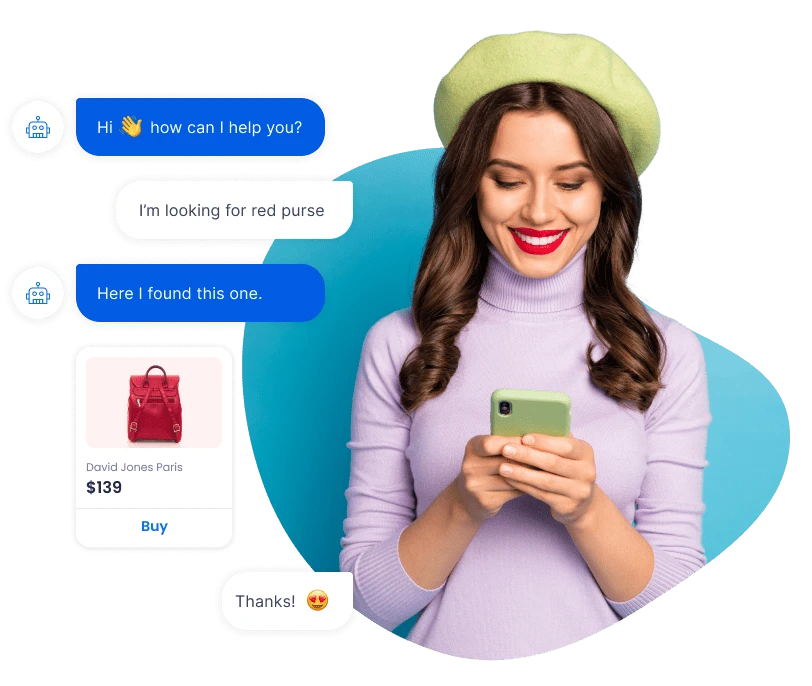
Various Industries Benefit from
our Chatbot Development Services
Our chatbot development services benefit both the customers and businesses.

E-Commerce
Improve sales. Use our eCommerce chatbot development solutions to respond to shoppers’ queries, recommend and find them products, manage orders, and reduce cart abandonment.

Human Resources
Free yourself from repetitive and tedious tasks. We offer chatbot apps that answer candidates’ FAQs, give them guidance and updates, and help HRs recruit and train candidates.

Healthcare
Shorten queue times. With chatbot app development solutions, check doctors’ availability, book appointments, update patients’ records, request prescription refills, and pay bills.

Banking & Finance
Check your account, transfer money, get financial advice, alert your bank for issues, get notified about new services and save time, with our chatbot app development solutions.

Travel & Hospitality
Provide an elite travel experience. Our chatbot app development solutions help select trips, book slots, answer flight queries, give details about offers, and send reminders.

Education
Lessen workload and increase engagement. Using chatbot apps for education help students in admission, complete assignments, remind about deadlines, promote courses, and more.
Top Chatbot Development Company
Facebook Chatbot Development
Twitter Chatbot Development
WhatsApp Chatbot Development
Instagram Chatbot Development
Slack Chatbot Development
Website Chatbot Development
The Need for Chatbot Development Services
Messaging is preferred by more than half of gadget users. Therefore, it’s worth having a chatbot. The chat interface is easy to use, offers fast answers to customers’ questions, is cost-effective, and is available 24/7.
Create a Chatbot for Your Company! – WHY?
Approximately 69% of customer queries are resolved by chatbots. This results in a 30% reduction in customer service costs. They also increased sales by 67%
.
What Makes Intelvue the Best Chatbot
Development Company?
With Intelvue’s chatbot software development, you go beyond just messaging and get:
Custom chatbots built by expert developers

Flexible engagement models to fit your needs

Timely project delivery and 24/7 support

Competitive pricing and high-quality services

Chatbot’s Essential Benefits
A chatbot comes with the following generous benefits:
- Routes visitors’ questions to the right team instantly.
- Provides 24/7 support and answers without long waiting.
- Uses natural and friendly language to answer queries.
- Gives level-headed polite guidance even to rude customers.
- Boosts sales by collecting customer data and qualifying leads.
- Asks for feedback and offers personalized experience.
- Saves time so you can improve workflows and productivity.
- Costs less than customer support team as it requires less staff.

Balance Automation with
a Human Touch
Add ChatBot to LiveChat in a couple of clicks. Transfer
customers to your support agents whenever needed.

Expert Chatbot Development Services. Get Today.
Frequently Asked Questions
FAQsA chatbot is a computer program designed to simulate conversation with human users, typically through text-based interfaces like messaging apps.
Chatbots can help automate customer service and support, provide 24/7 assistance, reduce response times, and improve overall customer satisfaction. They can also help generate leads and drive sales by engaging with potential customers.
Intelvue can develop chatbots for a variety of platforms, including Facebook Messenger, WhatsApp, Slack, Microsoft Teams, instagram, twitter, Website and many others. They can also be integrated into websites and mobile apps.
There are several programming languages that can be used to develop chatbots, including Python, Java, JavaScript, and C#. The team at Intelvue is skilled in a variety of programming languages.
Chatbot development time is dependent on several factors, including complexity, platform, and customization. Intelvue can provide a project timeline and estimated delivery date once they understand the scope of your chatbot project.
The cost of developing a chatbot can vary widely depending on the platform, programming language, complexity, and customization required. Intelvue can provide a project quote once they understand the scope of your chatbot project and your specific needs.
Success metrics for chatbots can vary depending on the goals of the business, but some common metrics include user engagement, conversation completion rates, customer satisfaction ratings, and sales or lead generation metrics. Intelvue can help you set up tracking and reporting features to measure the success of your chatbot.